Codifica ASCII. Tabella di codifica ASCII
sotto informazioni sulla codifica in un computer, è inteso il processo della sua conversione in un modulo, che rende possibile organizzare un trasferimento più conveniente, la memorizzazione o l'elaborazione automatica di questi dati. Diversi tavoli sono usati per questo scopo. La codifica ASCII è il primo sistema sviluppato negli Stati Uniti per lavorare con testo in inglese, che è stato successivamente distribuito in tutto il mondo. Di seguito la descrizione, le caratteristiche, le proprietà e l'ulteriore uso dell'articolo.
Visualizzazione e memorizzazione delle informazioni nel computer
I simboli sul monitor di un computer o su un gadget digitale mobile si formano sulla base di insiemi di forme vettoriali di vari segni e codici, consentendo di trovare tra loro il carattere che deve essere inserito nel posto giusto. È una sequenza di bit. Pertanto, ogni simbolo deve corrispondere inequivocabilmente a un insieme di zeri e a quelli che stanno in un certo ordine unico.
Ad
Com'è cominciato tutto
Storicamente, i primi computer erano di lingua inglese. Per codificare le informazioni simboliche in essi, era sufficiente utilizzare solo 7 bit di memoria, mentre per questo scopo veniva assegnato 1 byte composto da 8 bit. Il numero di caratteri compresi dal computer in questo caso era 128. Questi caratteri includevano l'alfabeto inglese con i segni di punteggiatura, i numeri e alcuni personaggi speciali La codifica inglese a sette bit con la tabella corrispondente (tabella codici), sviluppata nel 1963, era denominata Codice standard americano per lo scambio di informazioni. Solitamente per la sua designazione è stata usata l'abbreviazione "Codifica ASCII" che è ancora in uso.
Ad
Transizione a multilingue
Col passare del tempo, i computer hanno cominciato ad essere ampiamente utilizzati in paesi non di lingua inglese. A questo proposito, vi è la necessità di codifiche che consentano l'uso delle lingue nazionali. Si è deciso di non reinventare la ruota e di prendere l'ASCII come base. La tabella di codifica della nuova edizione è notevolmente migliorata. L'uso dell'ottavo bit ha permesso di tradurre 256 caratteri in un linguaggio informatico.
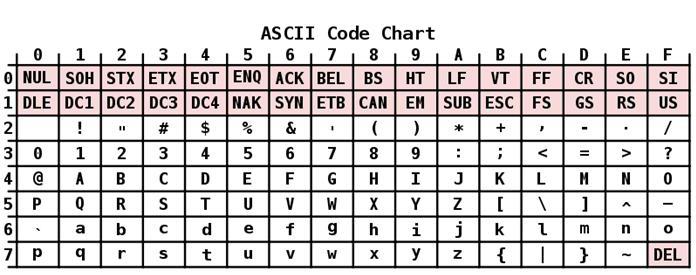
descrizione
La codifica ASCII ha una tabella divisa in 2 parti. Lo standard internazionale generalmente accettato è considerato solo il suo primo semestre. Include:
- Caratteri con numeri di sequenza da 0 a 31, codificati da sequenze da 00000000 a 00011111. Sono riservati ai caratteri di controllo che controllano il processo di visualizzazione del testo su uno schermo o stampante, segnale acustico, ecc.
- I caratteri con NN nella tabella da 32 a 127, codificati da sequenze da 00100000 a 01111111 costituiscono la parte standard della tabella. Questi includono uno spazio (N 32), lettere latine (minuscole e maiuscole), numeri a dieci cifre da 0 a 9, segni di punteggiatura, parentesi di diverso tipo e altri caratteri.
- Caratteri con numeri di sequenza da 128 a 255, codificati da sequenze da 10.000.000 a 1.111.111 Comprendono lettere di alfabeti nazionali diversi dal latino. Questa parte alternativa della tabella è la codifica ASCII utilizzata per convertire i caratteri russi in una forma computerizzata.
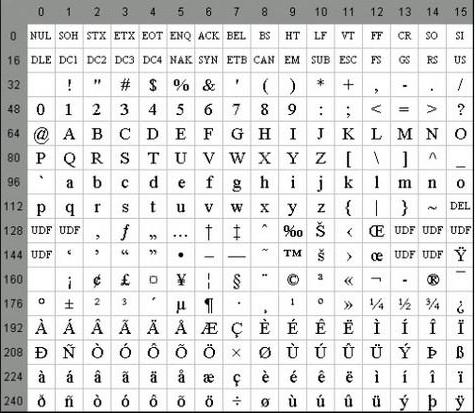
Alcune proprietà
Le caratteristiche speciali della codifica ASCII sono la differenza tra le lettere "A" - "Z" dei registri inferiore e superiore con un solo bit. Questa circostanza semplifica enormemente la conversione del registro e la sua verifica di appartenenza a un determinato intervallo di valori. Inoltre, tutte le lettere nel sistema di codifica ASCII sono rappresentate dai loro numeri di serie nell'alfabeto, che sono scritti in 5 cifre nel sistema di numeri binari, prima del quale per le lettere minuscole è 011 2 , e quella superiore è 010 2 .
Ad
Tra le caratteristiche della codifica ASCII può essere contato e la presentazione di 10 cifre - "0" - "9". Nel secondo sistema numerico, iniziano con 00112 e terminano con 2 numeri. Pertanto, 0101 2 equivale a un numero decimale di cinque, quindi il carattere "5" viene scritto come 0011 01012. Sulla base di quanto sopra, è possibile convertire facilmente numeri decimali binari in una stringa ASCII aggiungendo la sequenza di bit 00112 a ciascun nibble a sinistra.

"Unicode"
Come sai, per visualizzare i testi nelle lingue del gruppo del Sudest asiatico sono necessarie migliaia di caratteri. Tale numero non è descritto in alcun modo in un byte di informazioni, quindi anche le versioni estese di ASCII non potrebbero più soddisfare le crescenti esigenze degli utenti di paesi diversi.
Pertanto, è diventato necessario creare una codifica di testo universale, il cui sviluppo, in collaborazione con molti leader del settore IT globale, è stato preso dal consorzio Unicode. I suoi specialisti hanno creato il sistema UTF 32. In esso sono stati allocati 32 bit per codificare 1 carattere, che ha costituito 4 byte di informazioni. Lo svantaggio principale era un forte aumento della quantità di memoria richiesta in ben 4 volte, il che comportava molti problemi.
Ad
Allo stesso tempo, per la maggior parte dei paesi con lingue ufficiali appartenenti al gruppo indoeuropeo, il numero di caratteri pari a 2 32 è più che ridondante.
Come risultato dell'ulteriore lavoro degli specialisti del consorzio Unicode, è apparsa la codifica UTF-16. È diventata la possibilità di convertire le informazioni simboliche, che sono state disposte per tutti in termini di quantità di memoria richiesta e in termini di numero di caratteri codificati. Ecco perché UTF-16 è stato adottato per impostazione predefinita e richiede 2 byte per essere riservato per un carattere.
Anche questa versione abbastanza avanzata e di successo di Unicode ha alcuni inconvenienti e, dopo il passaggio da una versione estesa di ASCII a UTF-16, ha raddoppiato il peso del documento.
A questo proposito, è stato deciso di utilizzare la codifica a lunghezza variabile UTF-8. In questo caso, ogni carattere nel testo sorgente viene codificato in una sequenza da 1 a 6 byte di lunghezza.

Contattare il codice standard americano per lo scambio di informazioni
Tutti i segni alfabeto latino in lunghezza variabile UTF-8 codificata in 1 byte, come nel sistema di codifica ASCII.
Una caratteristica speciale di UTF-8 è che nel caso del testo in latino senza utilizzare altri caratteri, anche i programmi che non comprendono Unicode consentiranno comunque di leggerlo. In altre parole, la parte fondamentale della codifica del testo ASCII viene semplicemente trasferita alla nuova lunghezza variabile UTF. I caratteri cirillici in UTF-8 occupano 2 byte e, ad esempio, georgiani - 3 byte. Creando UTF-16 e 8, il problema principale della creazione di uno spazio di codice singolo nei font è stato risolto. Da allora, i produttori di caratteri devono solo riempire la tabella con forme vettoriali di simboli di testo in base alle loro esigenze.
Ad
In diversi sistemi operativi, viene data preferenza a diverse codifiche. Per poter leggere e modificare testi digitati in una codifica diversa, vengono utilizzati i programmi di conversione del testo in russo. Alcuni editor di testo contengono transcodificatori incorporati e consentono di leggere il testo indipendentemente dalla codifica.

Ora sai quanti caratteri sono in ASCII e come e perché è stato sviluppato. Certo, oggi lo standard Unicode è diventato il più diffuso al mondo. Tuttavia, non dobbiamo dimenticare che è stato creato sulla base di ASCII, quindi dovresti apprezzare il contributo dei suoi sviluppatori nel campo dell'IT.