Algoritmi genetici: l'essenza, la descrizione, gli esempi, l'applicazione
L'idea degli algoritmi genetici (GA) è apparsa molto tempo fa (1950-1975), ma sono diventati il vero oggetto di studio solo negli ultimi decenni. D. Holland è stato considerato il pioniere in questo campo, che ha preso in prestito molta genetica e l'ha adattato ai computer. Le GA sono ampiamente utilizzate nei sistemi di intelligenza artificiale, reti neurali e problemi di ottimizzazione.
Ricerca evolutiva
I modelli di algoritmi genetici sono stati creati sulla base dell'evoluzione della fauna selvatica e dei metodi di ricerca casuali. Allo stesso tempo, una ricerca casuale è un'implementazione della funzione di evoluzione più semplice: mutazioni casuali e selezione successiva.
Da un punto di vista matematico, la ricerca evolutiva non significa altro che la trasformazione di un insieme finito di soluzioni esistenti in una nuova. La funzione responsabile di questo processo è la ricerca genetica. La principale differenza di un tale algoritmo da una ricerca casuale è l'uso attivo delle informazioni accumulate durante le iterazioni (ripetizioni).
Perché abbiamo bisogno di algoritmi genetici
GA ha i seguenti obiettivi:
- spiegare i meccanismi di adattamento sia nell'ambiente naturale che nel sistema di ricerca intellettuale (artificiale);
- modellizzazione delle funzioni evolutive e loro applicazione per la ricerca efficace di soluzioni di vari problemi, principalmente di ottimizzazione.
Al momento, l'essenza degli algoritmi genetici e delle loro versioni modificate può essere chiamata la ricerca di soluzioni efficaci, tenendo conto della qualità del risultato. In altre parole, trovare il miglior equilibrio tra prestazioni e precisione. Ciò accade a causa del noto paradigma della "sopravvivenza dell'individuo più adatto" in condizioni incerte e sfocate.
Caratteristiche di GA
Elenchiamo le principali differenze di GA dalla maggior parte degli altri metodi per trovare la soluzione ottimale.
- lavorare con i parametri del compito, codificati in un certo modo e non direttamente con essi;
- la ricerca di una soluzione non avviene specificando l'approssimazione iniziale, ma nell'insieme di possibili soluzioni;
- usando solo la funzione obiettivo, senza ricorrere ai suoi derivati e modifiche;
- applicazione di un approccio probabilistico all'analisi, invece di un approccio strettamente deterministico.
Criteri di prestazione
Gli algoritmi genetici eseguono calcoli basati su due condizioni:
- Esegui un numero specificato di iterazioni.
- La qualità della soluzione trovata soddisfa i requisiti.
Se una di queste condizioni è soddisfatta, l'algoritmo genetico interromperà l'esecuzione di ulteriori iterazioni. Inoltre, l'uso di GA in varie regioni dello spazio soluzione consente loro di trovare soluzioni molto migliori con valori più appropriati della funzione obiettivo.
Ad
Terminologia di base
A causa del fatto che la GA è basata sulla genetica, la maggior parte della terminologia corrisponde ad essa. Qualsiasi algoritmo genetico funziona sulla base delle informazioni iniziali. L'insieme di valori iniziali è la popolazione t t = {n 1 , n 2 , ..., n n }, dove n i = {r 1 , ..., r v }. Esamineremo più in dettaglio:
- t è il numero di iterazione. t 1 , ..., t k - significa l'iterazione dell'algoritmo dal numero 1 al k, e ad ogni iterazione viene creata una nuova popolazione di soluzioni.
- n è la dimensione della popolazione P t .
- 1 , ..., п i - хромосома, особь, или организм. n 1 , ..., n i - cromosoma, individuo o organismo. Un cromosoma o catena è una sequenza codificata di geni, ognuno dei quali ha un numero di sequenza. Va tenuto presente che il cromosoma può essere un caso speciale di un individuo (organismo).
- r v sono geni che fanno parte della soluzione codificata.
- Un locus è il numero di sequenza di un gene in un cromosoma. L'allele è un valore genico che può essere sia numerico che funzionale.
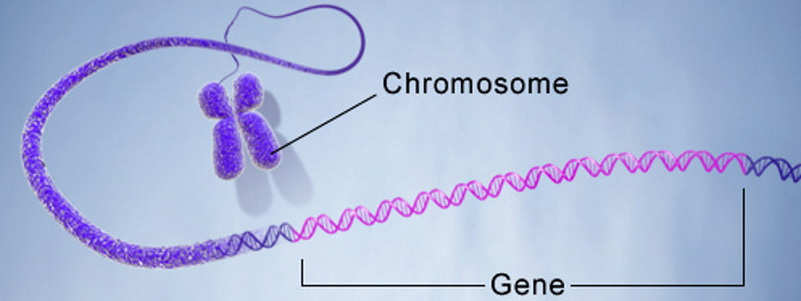
Cosa significa "codificato" nel contesto di GA? Di solito, qualsiasi valore è codificato sulla base di un alfabeto. L'esempio più semplice è la conversione di numeri dal sistema numerico decimale alla rappresentazione binaria. Pertanto, l'alfabeto è rappresentato come l'insieme {0, 1}, e il numero 157 10 sarà codificato dal cromosoma 10011101 2 , composto da otto geni.
Genitori e discendenti
I genitori sono gli elementi selezionati in base a una determinata condizione. Ad esempio, spesso questa condizione è un incidente. Gli elementi selezionati a causa delle operazioni di attraversamento e di mutazione danno origine a nuovi, che sono chiamati discendenti. Quindi, i genitori durante l'implementazione di un'iterazione dell'algoritmo genetico creano una nuova generazione.
Ad
Infine, l'evoluzione in questo contesto sarà l'alternanza di generazioni, ognuna delle quali nuova si distingue per un insieme di cromosomi in vista di una migliore forma fisica, vale a dire un'adeguata conformità alle condizioni specificate. Il background genetico generale nel processo di evoluzione è chiamato genotipo e la formazione della connessione dell'organismo con l'ambiente esterno è chiamata fenotipo.
Funzione di fitness
La magia dell'algoritmo genetico nella funzione fitness. Ogni individuo ha il suo valore, che può essere appreso attraverso la funzione di adattamento. Il suo compito principale è valutare questi valori per diverse soluzioni alternative e scegliere il migliore. In altre parole, il più adatto.
Nei problemi di ottimizzazione, la funzione del fitness è chiamata target, nella teoria del controllo si chiama errore, nella teoria dei giochi è una funzione di valore e così via. Ciò che verrà rappresentato esattamente come una funzione di adattamento dipende dal problema da risolvere.
Ad
Alla fine, si può concludere che gli algoritmi genetici analizzano una popolazione di individui, organismi o cromosomi, ognuno dei quali è rappresentato da una combinazione di geni (un insieme di alcuni valori), e cerca la soluzione ottimale, trasformando gli individui della popolazione attraverso l'evoluzione artificiale tra di loro.
Le deviazioni in una direzione o in un'altra dei singoli elementi nel caso generale sono conformi alla normale legge della distribuzione delle quantità. Allo stesso tempo, GA fornisce ereditarietà delle caratteristiche, le più adattate delle quali sono fisse, fornendo così la popolazione migliore.
Algoritmo genetico di base
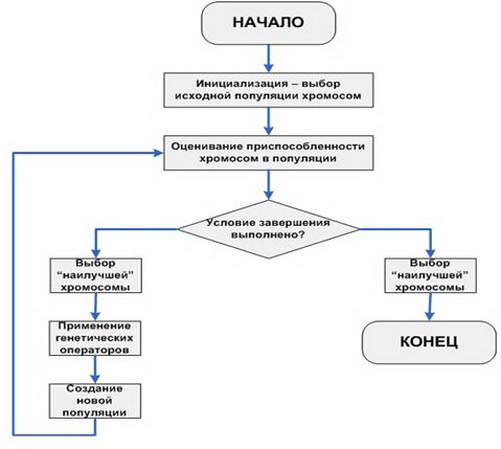
Decomponiamo in passaggi la più semplice (classica) GA.
- Inizializzazione dei valori iniziali, ovvero la definizione della popolazione primaria, l'insieme di individui con cui si verificherà l'evoluzione.
- Stabilire l'idoneità primaria di ogni individuo nella popolazione.
- Controllare le condizioni di terminazione per le iterazioni dell'algoritmo.
- Utilizzando la funzione di selezione.
- L'uso di operatori genetici.
- Creare una nuova popolazione.
- I passaggi da 2 a 6 vengono ripetuti in un ciclo fino a quando non viene soddisfatta la condizione necessaria, dopo di che si verifica la selezione dell'individuo più adatto.
Andiamo brevemente attraverso le piccole parti ovvie dell'algoritmo. Ci sono due condizioni per la risoluzione:
- Il numero di iterazioni.
- La qualità della soluzione.
Gli operatori genetici sono l'operatore di mutazione e l'operatore di crossover. Una mutazione modifica i geni casuali con una certa probabilità. Di regola, la probabilità di una mutazione ha un valore numerico basso. Parliamo di più della procedura dell'algoritmo genetico "crossing". Si verifica secondo il seguente principio:
Ad
- Per ogni coppia di genitori che contiene geni L, il punto di incrocio Tsk i viene selezionato casualmente.
- Il primo discendente è composto dall'unione di [1; Tsk i ] geni del primo genitore [Tsk i + 1 ; L] geni del secondo genitore.
- Il secondo discendente è composto nel modo inverso. Ora ai geni del secondo genitore [1; Tsk i ] aggiunge i geni del primo genitore nelle posizioni [Tsk i + 1 ; L].
Esempio banale
Risolviamo il problema con un algoritmo genetico usando l'esempio della ricerca di un individuo con il numero massimo di unità. Lascia che l'individuo sia composto da 10 geni. Assegniamo la popolazione primaria alla quantità di otto individui. Ovviamente, la persona migliore dovrebbe essere 1111111111. Ricomponiamo la decisione di GA.
- Inizializzazione. Scegli 8 individui a caso:
| n 1 | 1110010101 | n 5 | 0101000110 |
| n 2 | 1100111010 | n 6 | 0100110101 |
| n 3 | 1110011110 | n 7 | 0110111011 |
| n 4 | 1011000000 | n 8 | 0100001001 |
- Valutazione della forma fisica Ovviamente, nel nostro algoritmo genetico, la funzione fitness F conterà il numero di unità in ogni individuo. Quindi, abbiamo:
| n i | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| F (n i ) | 6 | 7 | 8 | 3 | 4 | 5 | 7 | 3 |
La tabella mostra che gli individui 3 e 7 hanno il maggior numero di unità e quindi sono i membri più adatti della popolazione a risolvere il problema. Dal momento che al momento non esiste una soluzione della qualità richiesta, l'algoritmo continua a funzionare. È necessario effettuare la selezione delle persone. Per facilitare la spiegazione, lascia che la selezione sia casuale e otteniamo un campione di individui {n 7 , n 3 , n 1 , n 7 , n 3 , n 7 , n 4 , n 2 } - questi sono i genitori della nuova popolazione.
- L'uso di operatori genetici. Di nuovo, per semplicità, assumiamo che la probabilità di mutazioni sia 0. In altre parole, tutti e 8 gli individui trasmettono i loro geni così come sono. Per attraversare, facciamo coppie di individui a caso: (n 2 , n 7 ), (n 1 , n 7 ), (n 3 , n 4 ) e (n 3 , n 7 ). Nello stesso modo casuale, i punti di incrocio per ogni coppia sono selezionati:
| paio | (p 2 , p 7 ) | (n 1 , n 7 ) | (p 3 , p 4 ) | (p 3 , p 7 ) |
| genitori | [1100111010] [0110111011] | [1110010101] [0110111011] | [1110011110] [1011000000] | [1110011110] [0110111011] |
| Tsk io | 3 | 5 | 2 | 8 |
| discendenti | [1100111011] [0110111010] | [1110011011] [0110110101] | [1111000000] [1010011110] | [1110011111] [0110111010] |
- Compilazione di una nuova popolazione composta da discendenti:
| n 1 | 1100111011 | n 5 | 1111000000 |
| n 2 | 0110111010 | n 6 | 1010011110 |
| n 3 | 1110011011 | n 7 | 1110011111 |
| n 4 | 0110110101 | n 8 | 0110111010 |
- Stimiamo l'idoneità di ogni individuo della nuova popolazione:
| n i | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| F (n i ) | 7 | 6 | 7 | 6 | 4 | 6 | 8 | 6 |
Ulteriori azioni sono ovvie. La cosa più interessante in GA è, se stimiamo il numero medio di unità in ogni popolazione. Nella prima popolazione, in media, c'erano 5.375 unità per ogni individuo, nella popolazione dei discendenti - 6,25 unità per individuo. E tale caratteristica sarà osservata anche se durante le mutazioni e l'attraversamento della persona con il maggior numero di unità nella prima popolazione si perde.
Piano di attuazione
La creazione di un algoritmo genetico è un compito piuttosto complicato. Innanzitutto, elencheremo il piano sotto forma di passaggi, dopo di che esamineremo ciascuno di essi in modo più dettagliato.
- Definizione di rappresentazione (alfabeto).
- Definizione di operatori di cambiamento casuale.
- Definizione di sopravvivenza degli individui.
- Generazione della popolazione primaria.
La prima fase dice che l'alfabeto in cui tutti gli elementi di una serie di soluzioni o di popolazione saranno codificati deve essere abbastanza flessibile da consentire le necessarie permutazioni casuali da eseguire nello stesso momento e valutare l'idoneità degli elementi, sia primari che quelli che hanno attraversato le modifiche. È matematicamente stabilito che è impossibile creare un alfabeto ideale per questi scopi, pertanto la sua compilazione è uno dei passaggi più difficili e cruciali per garantire un funzionamento GA stabile.
Ad

È ugualmente difficile definire le dichiarazioni di cambiamento e creare discendenti. Ci sono molti operatori che sono in grado di eseguire le azioni richieste. Ad esempio, è noto dalla biologia che ogni specie può riprodursi in due modi: sessualmente (incrociando) e asessuale (mediante mutazioni). Nel primo caso, i genitori si scambiano materiale genetico, nel secondo si verificano mutazioni determinate dai meccanismi interni del corpo e dall'influenza esterna. Inoltre, possono essere utilizzati modelli di riproduzione che non esistono nella fauna selvatica. Ad esempio, usa i geni di tre o più genitori. Allo stesso modo, l'incrocio di una mutazione in un algoritmo genetico può incorporare un meccanismo diverso.
La scelta di un metodo di sopravvivenza può essere estremamente ingannevole. Ci sono molti modi nell'algoritmo genetico per la riproduzione. E, come dimostra la pratica, la regola della "sopravvivenza del più adatto" non è sempre la migliore. Quando si risolvono problemi tecnici complessi, spesso si scopre che la soluzione migliore proviene da una moltitudine di media o anche peggio. Pertanto, è spesso accettato di utilizzare un approccio probabilistico, che afferma che la soluzione migliore ha una migliore possibilità di sopravvivenza.

L'ultimo stadio fornisce la flessibilità dell'algoritmo, che nessun altro ha. La popolazione iniziale di soluzioni può essere definita sia sulla base di qualsiasi dato conosciuto, sia in modo completamente casuale, semplicemente riorganizzando i geni all'interno degli individui e creando individui casuali. Tuttavia, vale sempre la pena ricordare che l'efficacia dell'algoritmo dipende dalla popolazione iniziale.
efficacia
L'efficacia dell'algoritmo genetico dipende interamente dalla correttezza dei passaggi descritti nel piano. Un elemento particolarmente influente qui è la creazione di una popolazione primaria. Ci sono molti approcci per questo. Ne descriviamo alcuni:
- Creazione di una popolazione completa che includerà tutti i tipi di opzioni per gli individui in una determinata area.
- Creazione casuale di individui in base a tutti i valori validi.
- Creazione casuale di punti di individui, quando tra i valori accettabili viene selezionato l'intervallo per la generazione.
- Combinare i primi tre modi per creare una popolazione.

Quindi, possiamo concludere che l'efficacia degli algoritmi genetici dipende in gran parte dall'esperienza del programmatore in questa materia. Questo è allo stesso tempo uno svantaggio degli algoritmi genetici e il loro vantaggio.