Qual è il potere dell'alfabeto
L'alfabeto in informatica è il sistema dei segni, con il quale è possibile inviare un messaggio informativo. Per comprendere l'essenza di questa definizione, ecco alcuni fatti teorici aggiuntivi:
- Ogni messaggio è composto da un alfabeto. Ad esempio, questo articolo è un messaggio. Quindi consiste dei caratteri dell'alfabeto russo.
- Sotto il simbolo possiamo capire la minima particella significativa dell'alfabeto. Anche le particelle indivisibili sono chiamate atomi. I caratteri dell'alfabeto russo sono "a", quindi "b", "c" e così via.
- In teoria, l'alfabeto non ha bisogno di essere codificato in alcun modo. Ad esempio, in un libro stampato, i simboli dell'alfabeto significano se stessi, il che significa che non hanno alcuna codifica.

Ma in pratica abbiamo il seguente: il computer non capisce cosa siano le lettere. Pertanto, per trasmettere un messaggio informativo, deve prima essere codificato in un linguaggio comprensibile al computer. Per andare avanti, è necessario introdurre termini aggiuntivi.
Ad
Qual è il potere dell'alfabeto
Per potenza alfabetica si intende il numero totale di caratteri in esso contenuti. Per scoprire qual è il potere dell'alfabeto, devi solo contare il numero di caratteri al suo interno. Scopriamolo. Per l'alfabeto russo, la potenza dell'alfabeto è di 33 o 32 caratteri, se non si usa "e".
Supponiamo che tutti i caratteri nel nostro alfabeto si incontrino con uguale probabilità. Questa ipotesi può essere intesa come segue: supponiamo di avere una borsa con i cubi firmati. Il numero di cubetti in esso è infinito e ognuno è firmato con un solo simbolo. Quindi, con una distribuzione uniforme, non importa quanti cubetti usciamo dal sacchetto, il numero di cubi con simboli diversi sarà lo stesso, o tenderà a questo con un aumento del numero di cubetti che tiriamo fuori dal sacchetto.
Ad
Valutazione del peso dei messaggi informativi
Quasi cento anni fa, l'ingegnere americano Ralph Hartley ricavava una formula con cui puoi valutare quantità di informazioni nel messaggio. La sua formula funziona per eventi altrettanto probabili e assomiglia a questo:
i = log 2 M
Dove "i" è il numero di atomi di informazioni indivisibili (bit) nel messaggio, "M" è il potere dell'alfabeto. Seguiamo. Con l'aiuto delle trasformazioni matematiche, possiamo determinare che il potere dell'alfabeto può essere calcolato come segue:
M = 2 i
Questa formula in forma generale stabilisce la connessione tra il numero di eventi ugualmente probabili "M" e la quantità di informazioni "i".
Calcola il potere
Molto probabilmente, si sa già dal corso di informatica della scuola che nei moderni sistemi di calcolo costruiti sull'architettura von Neumann, viene utilizzato un sistema di codifica delle informazioni binarie. Sia i programmi che i dati sono codificati in questo modo.
Per presentare il testo nel sistema informatico, utilizzare un codice uniforme di otto bit. Un codice è considerato uniforme perché contiene un insieme fisso di elementi - 0 e 1. I valori in tale codice sono specificati da un ordine specifico di questi elementi. Con l'aiuto di un codice a otto bit, possiamo codificare messaggi che pesano 256 bit, perché con la formula di Hartley: M 8 = 2 8 = 256 bit di informazione.
Questa situazione con la codifica dei caratteri nel codice binario si è sviluppata storicamente. Ma teoricamente potremmo usare altri alfabeti per rappresentare i dati. Quindi, ad esempio, nell'alfabeto a quattro lettere, ogni personaggio avrebbe un peso non di uno, ma di due bit, in un alfabeto di otto caratteri - 3 bit e così via. Questo viene calcolato usando il logaritmo binario sopra indicato ( i = log 2 M ).
Ad
Poiché nell'alfabeto con una capacità di 256 bit, vengono assegnate otto cifre binarie per designare un carattere, è stato deciso di introdurre un'ulteriore misura di informazioni - byte. Un byte contiene un carattere della tabella di codici ASCII e contiene otto bit.
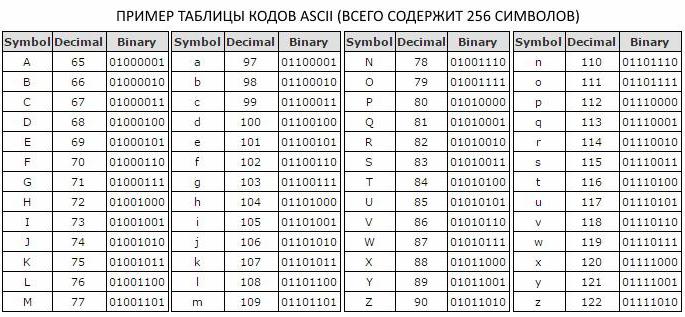
Come misurare le informazioni
в прописном и строчном варианте, цифры, символы знаков препинания и другие базовые символы. La codifica a otto bit dei messaggi di testo, utilizzata nella tabella di codici ASCII, consente di adattare l'insieme di base dei caratteri latini e cirillici in maiuscolo e minuscolo, numeri, segni di punteggiatura e altri caratteri di base.
Per misurare quantità maggiori di dati, utilizzare prefissi speciali per le parole byte e bit. Tali allegati sono mostrati nella tabella seguente:
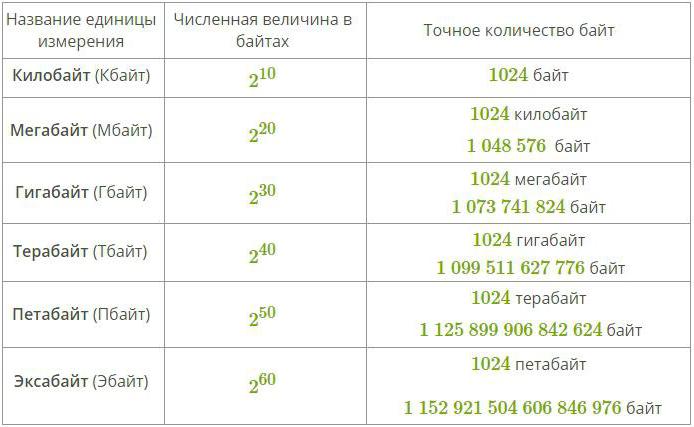
Molte persone che hanno studiato fisica sosterranno che sarebbe razionale usare prefissi classici per designare unità di informazioni (come kilo e mega), ma in realtà questo non è del tutto corretto, perché tali prefissi ai valori denotano la moltiplicazione di uno o un altro grado di dieci quando il sistema binario di misure è usato ovunque nell'informatica.
Nomi corretti delle unità di dati
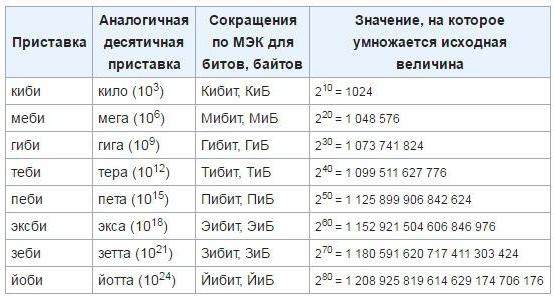
Al fine di eliminare inesattezze e inconvenienti, nel marzo 1999 la Commissione internazionale per l'ingegneria elettrica ha approvato nuove unità per le unità, che sono utilizzate per determinare la quantità di informazioni nella tecnologia di calcolo elettronico. Tali prefissi sono "mebi", "kibi", "gibi", "tebi", "eksbi", "petit". Finora, queste unità non hanno ancora messo radici, quindi molto probabilmente è necessario del tempo per l'introduzione di questo standard e l'inizio di un uso diffuso. Come rendere la transizione dalle unità classiche alla nuova approvazione, è possibile determinare la seguente tabella:
Ad
Supponiamo di avere un testo che contiene caratteri K. Quindi, utilizzando l'approccio alfabetico, è possibile calcolare la quantità di informazioni V, che contiene. Sarà uguale al prodotto del potere dell'alfabeto dal peso informativo di un personaggio in esso.
Con la formula di Hartley, sappiamo come calcolare la quantità di informazioni attraverso il logaritmo binario. Supponendo che il numero di caratteri dell'alfabeto sia uguale a N e il numero di caratteri nel record del messaggio informativo sia uguale a K, otteniamo la seguente formula per il calcolo del volume di informazioni del messaggio:
V = K ⋅ log 2 N
L'approccio alfabetico indica che il volume delle informazioni dipenderà solo dalla potenza dell'alfabeto e dalla dimensione dei messaggi (cioè il numero di caratteri in esso contenuti), ma non sarà in alcun modo collegato al contenuto semantico di una persona.
Esempi di calcolo della potenza
In classe l'informatica spesso dà il compito di trovare la potenza dell'alfabeto, la lunghezza del messaggio o il volume delle informazioni. Ecco uno di questi compiti:
"Un file di testo occupa 11 KB di spazio su disco e contiene 11264 caratteri. Determina la potenza dell'alfabeto di questo file di testo."
Quale sarà la soluzione, puoi vedere nella foto qui sotto.

Pertanto, l'alfabeto con una capacità di 256 caratteri contiene solo 8 bit di informazioni, che in informatica è chiamato un byte. Byte descrive 1 carattere della tabella ASCII, che, se ci pensi, non è molto.
Ad
È un byte molto o poco?
I moderni archivi di dati come i data center di Google e Facebook contengono non meno di dozzine di petabyte di informazioni. La quantità esatta di dati, tuttavia, sarà difficile da calcolare anche da soli, poiché in tal caso sarà necessario interrompere tutti i processi sui server e chiudere gli utenti l'accesso alla registrazione e alla modifica delle informazioni personali.

Ma per poter immaginare una quantità così inconcepibile di dati, è necessario comprendere chiaramente che tutto è fatto di piccoli dettagli. È necessario capire qual è la potenza dell'alfabeto (256) e quanti bit contengono 1 byte di informazioni (come ricordi, 8).