Codice genetico: descrizione, caratteristiche, storia della ricerca
Ogni organismo vivente ha un set speciale di proteine. Alcuni composti nucleotidici e la loro sequenza in Molecola di DNA formare il codice genetico. Trasmette informazioni sulla struttura della proteina. Nella genetica è stato adottato un determinato concetto. Secondo lei, un enzima (polipeptide) corrispondeva a un gene. Va detto che la ricerca sugli acidi nucleici e le proteine è stata condotta su un periodo abbastanza lungo. Più avanti nell'articolo daremo un'occhiata più da vicino al codice genetico e alle sue proprietà. Sarà anche fornita una breve cronologia di ricerca. 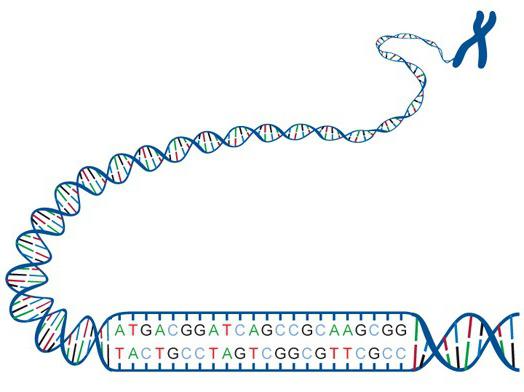
terminologia
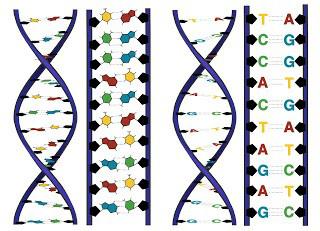
Un codice genetico è un metodo per codificare una sequenza di proteine amminoacidiche che coinvolgono una sequenza nucleotidica. Questo metodo di formazione delle informazioni è caratteristico di tutti gli organismi viventi. Le proteine sono sostanze organiche presenti in natura ad alto peso molecolare. Questi composti sono presenti anche negli organismi viventi. Sono costituiti da 20 tipi di amminoacidi, che sono chiamati canonici. Gli amminoacidi sono disposti in una catena e collegati in una sequenza strettamente definita. Definisce struttura proteica e le sue proprietà biologiche. Ci sono anche diverse catene di aminoacidi nella proteina. 
DNA e RNA
L'acido desossiribonucleico è una macromolecola. È responsabile della trasmissione, conservazione e implementazione di informazioni ereditarie. Il DNA utilizza quattro basi azotate. Questi includono adenina, guanina, citosina, timina. L'RNA consiste degli stessi nucleotidi, oltre a quello che contiene la timina. Invece, c'è un nucleotide contenente uracile (U). Le molecole di RNA e DNA sono catene di nucleotidi. A causa di questa struttura, si formano sequenze - "alfabeto genetico".
Ad
Implementazione di informazioni
Sintesi proteica, che è codificato dal gene, si realizza combinando l'mRNA sul modello del DNA (trascrizione). Inoltre, il trasferimento del codice genetico nella sequenza amminoacidica. Cioè, c'è una sintesi della catena polipeptidica sull'mRNA. Per crittografare tutti gli amminoacidi e segnalare la fine della sequenza proteica sono sufficienti 3 nucleotidi. Questa catena è chiamata tripletta. 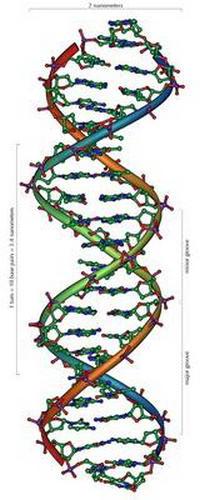
Storia della ricerca
Studio delle proteine e acidi nucleici ha tenuto un lungo tempo. Verso la metà del XX secolo, infine, apparvero le prime idee sulla natura del codice genetico. Nel 1953, si è scoperto che alcune proteine sono composte da sequenze di amminoacidi. È vero, non potevano ancora determinare il loro numero esatto, e c'erano numerose controversie su questo argomento. Nel 1953, due articoli furono pubblicati dagli autori Watson e Crick. Il primo dichiarò la struttura secondaria del DNA, il secondo parlò della sua copia ammissibile usando la sintesi della matrice. Inoltre, l'accento è stato posto sul fatto che una specifica sequenza di basi è un codice che trasporta informazioni ereditarie. Il fisico americano e sovietico Georgy Gamov ha permesso l'ipotesi della codifica e ha trovato un metodo per la sua verifica. Nel 1954, il suo lavoro fu pubblicato, durante il quale avanzò una proposta per stabilire corrispondenze tra le catene di amminoacidi laterali e "buchi" che hanno una forma romboidale, e usarlo come meccanismo di codifica. Poi fu chiamato rombico. Spiegando il suo lavoro, Gamow ha ammesso che il codice genetico potrebbe essere una tripletta. La fisica del lavoro fu una delle prime tra quelle che furono considerate vicine alla verità. 
classificazione
Dopo diversi anni, sono stati proposti vari modelli di codici genetici, che rappresentano due tipi: sovrapposti e non sovrapposti. La base del primo era l'ingresso di un nucleotide in diversi codoni. Ad esso appartiene il codice genetico triangolare, sequenziale e maggiore minore. Il secondo modello riguarda due tipi. Non sovrapposte sono combinatorie e "codice senza virgole". La prima variante è basata sulla codifica degli amminoacidi delle triplette nucleotidiche e la cosa principale è la sua composizione. Secondo il "codice senza virgole", alcune terzine corrispondono agli amminoacidi e il resto no. In questo caso, si riteneva che se fossero state disposte sequenzialmente delle terzine significative, altre che erano in una cornice di lettura diversa non sarebbero necessarie. Gli scienziati ritenevano che esistesse la possibilità di selezionare una sequenza nucleotidica che soddisfasse questi requisiti e che esistessero esattamente 20 terzine.  Anche se Gamow e colleghi hanno messo in discussione un modello del genere, è stato considerato il più corretto per i prossimi cinque anni. All'inizio della seconda metà del XX secolo apparvero nuovi dati che rivelarono alcuni difetti nel "codice senza virgola". È stato scoperto che i codoni sono in grado di provocare la sintesi proteica in vitro. Verso il 1965 fu compreso il principio di tutte le 64 triplette. Di conseguenza, ha scoperto la ridondanza di alcuni codoni. In altre parole, la sequenza amminoacidica è codificata da diverse triplette.
Anche se Gamow e colleghi hanno messo in discussione un modello del genere, è stato considerato il più corretto per i prossimi cinque anni. All'inizio della seconda metà del XX secolo apparvero nuovi dati che rivelarono alcuni difetti nel "codice senza virgola". È stato scoperto che i codoni sono in grado di provocare la sintesi proteica in vitro. Verso il 1965 fu compreso il principio di tutte le 64 triplette. Di conseguenza, ha scoperto la ridondanza di alcuni codoni. In altre parole, la sequenza amminoacidica è codificata da diverse triplette.
Caratteristiche distintive
Le proprietà del codice genetico includono:
- Tripletta. Una sequenza di tre nucleotidi è una significativa unità di codice.
- Continuità. Le terzine non hanno segni di punteggiatura c'è una lettura continua di informazioni.
- Disgiunzione. Il nucleotide fa parte di una sola tripletta. In alcuni geni di virus, batteri e mitocondri, sono codificate diverse proteine e si verifica una lettura di spostamento del frame.
- L'unicità. Un codone specifico corrisponde a non più di un amminoacido. Vero, l'UGA Euplotescrassus può codificare cisteina e silenocisteina.
- Degenerazione. Un amminoacido specifico corrisponde a diversi codoni.
- Versatilità. Il codice genetico opera secondo lo stesso principio in organismi di varia complessità. Questa è l'essenza dell'ingegneria genetica. Tuttavia, ci sono alcune eccezioni.
- Immunità al rumore Le sostituzioni nucleotidiche mutazionali sono conservative e radicali. Il primo non porta a un cambiamento nella classe dell'amminoacido codificato. Le mutazioni radicali cambiano la classe dell'amminoacido codificato.
variazioni
Per la prima volta, la deviazione del codice genetico da quella standard è stata scoperta nel 1979 mentre studiava i geni mitocondriali nel corpo umano. Inoltre, sono state identificate varianti più simili, tra cui una moltitudine di codici mitocondriali alternativi. Questi includono la decodifica del codone di stop CAA, che viene usato come una definizione di triptofano nei micoplasmi. GUG e CCG in archaea e batteri sono spesso usati come varianti iniziali. A volte i geni codificano una proteina da un codone iniziale che differisce dallo standard usato da questa specie. Inoltre, in alcune proteine, selenocisteina e pirrolisina, che sono aminoacidi non standard, sono inserite dal ribosoma. Legge il codone di stop. Dipende dalle sequenze trovate nell'mRNA. Attualmente, la selenocisteina è considerata il 21 °, pirrolizan - il 22 ° amminoacido presente nella composizione delle proteine.
Caratteristiche comuni del codice genetico
Tuttavia, tutte le eccezioni sono rare. Negli organismi viventi, principalmente il codice genetico ha un numero di caratteristiche comuni. Questi includono la composizione del codone, che comprende tre nucleotidi (i primi due appartengono al decisivo), il trasferimento di codoni tRNA e ribosomi nella sequenza amminoacidica.