La replica è cosa?
Oggi parleremo di cosa sia la replica dei dati. Come viene usato? Che tipi ci sono? Nonostante il fatto che questo termine possa essere incontrato più spesso nella sfera informatica, denota anche alcuni processi che avvengono anche in campi opposti della scienza. Vediamo la replica: cos'è questo?
origine
Il termine stesso deriva dal latino, dalla parola replicatio - rinnovo, ripetizione. Quindi, possiamo concludere che il concetto moderno di replica significa più o meno la stessa cosa - aumentando il numero, copiando. La replica è un processo che consente di creare una copia di un oggetto.
Iniziamo con concetti più semplici. Il processo di replica dei CD è, infatti, replicato e distribuito a causa di un aumento della produzione e quindi della quantità di stampigliatura prodotta dalla pianta.
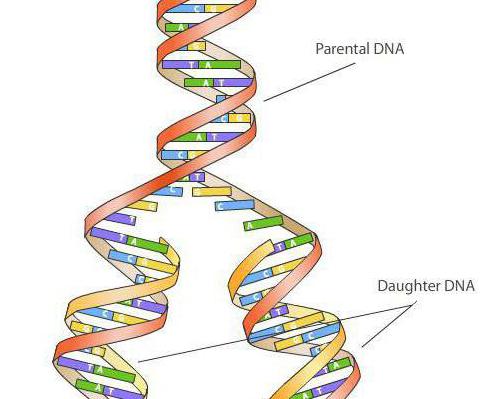
In medicina e biologia, la replicazione è il processo che è la base divisione cellulare, il che si traduce in un raddoppio Molecole di DNA A causa di ciò, esiste una copia completa del materiale genetico da trasmettere di generazione in generazione.
Ad
ICT
In un ambiente informatico, la replica è uno dei motivi per cui gli amministratori di sistema possono dormire tranquillamente. Questo processo è molto simile al backup dei dati del server, ma in realtà è solo una parte di esso. È possibile distinguere due tipi di replica: sincrona e asincrona. Qual è l'essenza di questo processo?

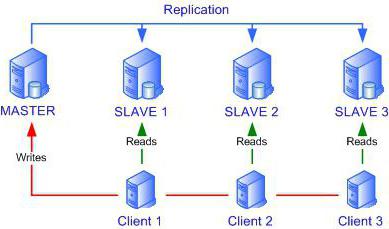
La replica è una tecnica per ridimensionare i database. Sta nel fatto che i dati dal server principale ("master") vengono continuamente copiati su uno o più secondari ("slave"). Di conseguenza, le applicazioni client possono utilizzare i dati non da un nodo di rete, ma da diversi, che a loro volta riducono notevolmente il carico di lavoro.
classificazione
Esistono due tipi di replica praticati. Il primo è la replica come master slave. Questo schema utilizza il principio che tutte le modifiche si verificano solo su un server: il "master". E poi vengono copiati su server replicanti - schiavi. Quindi, ognuno di loro svolge la sua funzione.
Ad
- Se è necessario apportare modifiche al server (scrivere, eliminare, aggiornare i dati), il programma fa riferimento al "master".
- Se hai solo bisogno di ottenere un campione di dati (leggi), saranno ottenuti da uno qualsiasi dei server secondari.
Questo schema è abbastanza conveniente. In caso di problemi sul "master", tutte le operazioni di scrittura devono essere impostate su "slave", vale anche il contrario. I server sono completamente intercambiabili. Quando si utilizza questo tipo di replica, è possibile ospitare fino a 20 server "slave". Spesso questo tipo viene utilizzato per il backup dei dati.
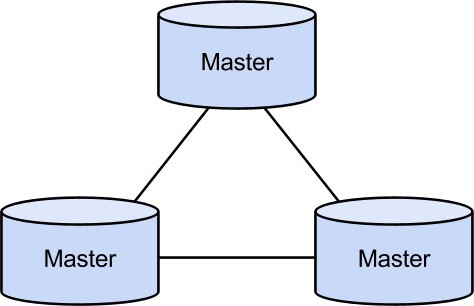
Il secondo tipo di replica è il "master master". Implica che l'utente accede a un server casuale e quindi si scambiano dati tra loro. Questo schema è molto poco interessante dal punto di vista della sicurezza, dal momento che se uno dei server fallisce, nella maggior parte dei casi tutti i dati vengono persi.
asincronia
Nonostante tutti i vantaggi di questa tecnica, la replica SQL presenta diversi svantaggi. Uno di questi è operazioni asincrone. Ciò significa che c'è un ritardo nel trasferimento dal server master allo "slave". È abbastanza difficile determinare la velocità con cui i nuovi dati appariranno sullo "slave", perché il ritardo potrebbe essere alquanto insignificante e forse molto ampio. Se è necessario lavorare continuamente con i dati, è necessario utilizzare una chiamata allo stesso server "master" e non leggere i dati dallo "slave".
Ad
Per evitare ciò, è possibile utilizzare la modalità sincrona. Il suo principio è che tutte le richieste arrivano al server principale e le risposte provengono dallo "schiavo". Pertanto, è garantita la copia completa dei dati sul nodo secondario. Naturalmente, questo porta a una grande perdita di velocità, tuttavia, semplifica l'intero sistema.
manualmente
Poiché la replicazione è un processo complesso e sfaccettato, è molto difficile tenere conto di tutti gli aspetti di questa metodologia. Inoltre, non è una tecnologia specifica, ma piuttosto una serie di istruzioni e azioni specifiche. Inoltre, alcune tecnologie informatiche non sono in grado di funzionare in linea di principio con la replica.
Per tali situazioni c'è una tecnica speciale. Quando si sviluppa un'applicazione, è possibile aggiungere l'auto-replica. L'applicazione deve inviare richieste a più server contemporaneamente, in modo da evitare problemi associati alla replica e ignorare la sua assenza tra i server, ottenendo tutti i dati necessari.
In caso di malfunzionamenti su uno dei server, è necessario disabilitare il server non funzionante e abilitare la replica tramite il tipo "master slave". Ciò ti consentirà di sincronizzare tutte le repliche e organizzare i dati. Dopo aver riparato il server danneggiato e la sincronizzazione, è possibile riaccenderlo al sistema e riportare tutto alla normalità.
Il risultato
L'uso della replica nei sistemi di database non è sempre giustificato. I meccanismi complicati di scrittura-lettura riducono la velocità di elaborazione delle richieste o riducono l'affidabilità del sistema. elaborazione delle informazioni. Quindi, se hai bisogno di creare una copia di backup del tuo server di lavoro, fallo regolarmente meglio e dormi tranquillamente.