Tabella dei caratteri libera Unicode
Unicode è uno standard internazionale per la codifica dei caratteri che consente di visualizzare i testi in modo uniforme su qualsiasi computer del mondo, indipendentemente dal linguaggio di sistema utilizzato su di esso.
Le basi
Per capire perché è necessaria una tabella dei simboli Unicode, esaminiamo innanzitutto il meccanismo per la visualizzazione del testo su uno schermo monitor. Un computer, come sappiamo, elabora tutte le informazioni in forma digitale e deve essere visualizzato in forma grafica per una percezione corretta da parte di una persona. Pertanto, per consentirci di leggere questo testo, dobbiamo risolvere almeno due problemi:
- Codifica i caratteri stampabili in forma digitale.
- Fornire al sistema operativo la capacità di abbinare il modulo digitale con simboli vettoriali, in altre parole, trovare le lettere corrette.
Prime codifiche
L'antenato di tutte le codifiche è considerato ASCII americano. Descriveva l'alfabeto latino usato in inglese segni di punteggiatura e Numeri arabi Sono stati usati i 128 caratteri che sono diventati la base per ulteriori sviluppi - anche la moderna tabella dei simboli Unicode li usa. Le lettere dell'alfabeto latino hanno occupato la prima posizione in qualsiasi codifica.

In totale, ASCII consentiva di salvare 256 caratteri, ma poiché i primi 128 erano in caratteri latini, gli altri 128 iniziarono ad essere usati in tutto il mondo per creare standard nazionali. Ad esempio, in Russia, sono stati creati CP866 e KOI8-R sulla base. Tali variazioni erano chiamate versioni estese di ASCII.
Ad
Code Pages e Crackdowns
Ulteriore sviluppo della tecnologia e l'emergere di GUI ha portato al fatto che l'American Institute of Standardization è stato creato per codificare ANSI. Per gli utenti russi, specialmente per esperienza, la sua versione è conosciuta come Windows 1251. Per la prima volta in essa è stato utilizzato il concetto di "code page". È stato con l'aiuto delle code page che contenevano i simboli degli alfabeti nazionali, oltre al latino, che si stabiliva una "comprensione reciproca" tra computer usati in diversi paesi.
Tuttavia, la presenza di un gran numero di codifiche differenti utilizzate per una lingua ha iniziato a causare problemi. C'erano i cosiddetti krakozyabry. Sono nati da una mancata corrispondenza tra la code page originale, in cui sono state create le informazioni e la code page utilizzata per impostazione predefinita sul computer dell'utente finale.
Ad

Ad esempio, possono essere citate le codifiche Cirillico sopra citate CP866 e KOI8-R. Le lettere in esse differivano posizioni di codice e principi di collocamento. Nel primo erano disposti in ordine alfabetico e nel secondo in modo arbitrario. Puoi immaginare cosa stia accadendo davanti agli occhi di un utente che ha tentato di aprire tale testo senza avere la code page necessaria o se è stato erroneamente interpretato dal computer.
Crea Unicode
La diffusione di Internet e delle tecnologie correlate, come l'e-mail, ha portato al fatto che alla fine la situazione con la distorsione dei testi ha cessato di soddisfare tutti. Le principali aziende IT hanno costituito Unicode Consortium ("Unicode Consortium"). La tabella dei personaggi, presentata loro nel 1991 con il nome UTF-32, consentiva di archiviare più di un miliardo di personaggi unici. Questo è stato il passo più importante sulla decifrazione dei testi.
Ad

Tuttavia, la prima tabella universale dei codici carattere Unicode UTF-32 non era ampiamente utilizzata. Il motivo principale era la ridondanza delle informazioni memorizzate. È stato calcolato rapidamente per i paesi in cui alfabeto latino codificato usando la nuova tabella universale, il testo occuperà uno spazio quattro volte maggiore rispetto a quando si utilizza la tabella ASCII estesa.
Sviluppo Unicode
La seguente tabella di simboli Unicode UTF-16 ha risolto questo problema. La codifica al suo interno è stata eseguita a metà del numero di bit, ma allo stesso tempo il numero di combinazioni possibili è diminuito. Invece di miliardi di caratteri, consente di risparmiare solo 65.536. Tuttavia, è stato un tale successo che questo numero, in base alla decisione del Consorzio, è stato determinato come spazio di archiviazione dei caratteri di base dello standard Unicode.
Nonostante questo successo, UTF-16 non andava bene a tutti, dal momento che la quantità di informazioni memorizzate e trasmesse era ancora il doppio. La soluzione universale era UTF-8, una tabella di caratteri Unicode a lunghezza variabile. Questo può essere definito un passo avanti in questo settore.

Pertanto, con l'introduzione degli ultimi due standard, la tabella dei simboli Unicode ha risolto il problema di uno spazio di codice singolo per tutti i tipi di carattere attualmente utilizzati.
Unicode per la lingua russa
A causa della lunghezza variabile del codice utilizzato per visualizzare i caratteri, il latino viene codificato in Unicode allo stesso modo del suo progenitore ASCII, cioè, in un solo punto. Per altri alfabeti, l'immagine potrebbe essere diversa. Ad esempio, i segni dell'alfabeto georgiano sono usati per codificare tre byte e i segni dell'alfabeto cirillico - due. Tutto questo è possibile nel quadro dell'utilizzo dello standard Unicode UTF-8 (tabella dei simboli). La lingua russa o l'alfabeto cirillico occupa 448 posizioni nello spazio codice generale diviso in cinque blocchi.
Ad
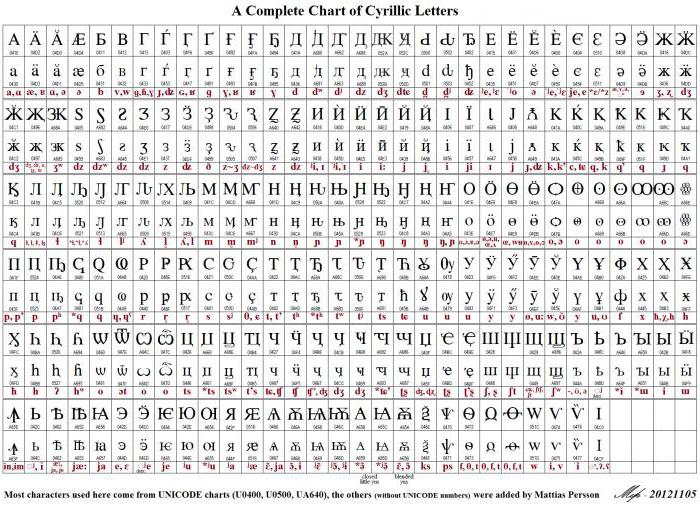
Questi cinque blocchi includono il principale alfabeto cirillico e slavo ecclesiastico, oltre a lettere aggiuntive di altre lingue usando il cirillico. Un numero di posizioni è assegnato per visualizzare le vecchie forme di rappresentare le lettere cirilliche, mentre 22 posizioni del numero totale rimangono libere.
La versione corrente di Unicode
Con la soluzione del suo compito principale, che era quello di standardizzare i caratteri e creare uno spazio di codice unico per loro, il consorzio non ha fermato il suo lavoro. Unicode è in continua evoluzione e crescita. L'ultima versione attuale di questo standard, 9.0, è stata rilasciata nel 2016. Comprendeva sei alfabeti aggiuntivi e ampliava la lista di emoji standardizzati.
Va notato che, al fine di semplificare la ricerca, anche il cosiddetto lingue morte. Hanno preso questo nome perché non ci sono persone per le quali sarebbero parenti. Questo gruppo include anche le lingue che sono arrivate fino ai nostri tempi solo sotto forma di monumenti scritti.
Ad
In linea di principio, chiunque può richiedere l'aggiunta di caratteri alle nuove specifiche Unicode. È vero, questo dovrà riempire una quantità decente di documenti di origine e impiegare molto tempo. Un esempio vivente di questo è la storia del programmatore Terence Eden. Nel 2013 ha chiesto l'inclusione nelle specifiche dei caratteri relativi alla designazione dei pulsanti di controllo dell'alimentazione del computer. Nella documentazione tecnica, sono stati utilizzati a partire dalla metà degli anni '70 del secolo scorso, ma fino a quando non appariva la specifica 9.0, non erano parte di Unicode.
Tabella dei simboli
Su ogni computer, indipendentemente dal sistema operativo utilizzato, viene utilizzata una tabella dei simboli Unicode. Come utilizzare queste tabelle, dove trovarle e perché possono essere utili all'utente medio?
Su Windows, la tabella dei simboli si trova nel menu "Strumenti". Nella famiglia Linux di sistemi operativi, di solito si trova nella sottosezione "Standard" e in MacOS nelle impostazioni della tastiera. Lo scopo principale di questa tabella è inserire i caratteri in documenti di testo che non si trovano sulla tastiera.
L'applicazione per tali tabelle può essere la più ampia: dall'introduzione di simboli tecnici e icone dei sistemi monetari nazionali alle istruzioni per la scrittura per l'applicazione pratica delle carte dei Tarocchi.
In conclusione
Unicode è usato ovunque ed è entrato nelle nostre vite insieme allo sviluppo di Internet e delle tecnologie mobili. Grazie al suo uso, il sistema delle comunicazioni inter-etniche è stato notevolmente semplificato. Possiamo dire che l'introduzione di Unicode è indicativa, ma completamente impercettibile dall'esempio dell'uso della tecnologia per il bene comune di tutta l'umanità.