Lettura file: file get funzione contenuto (PHP)
Formalmente, il contenuto del file diventa di costruzione PHP è simile al file, ma colloca il contenuto letto in una stringa, non in una serie di stringhe e consente di specificare un offset nel file da cui iniziare a leggere.
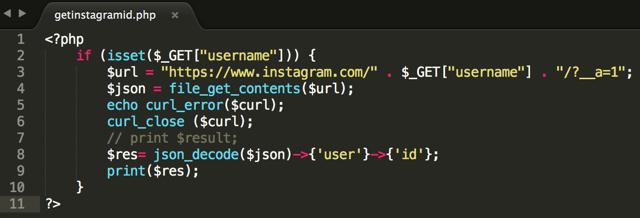
La lettura regolare di fopen / fgets / fclose diventa meno rilevante. È più comodo leggere il contenuto del file o l'intera pagina del sito e quindi eseguire le operazioni necessarie con esso. Il file PHP ottiene la costruzione del contenuto consente di creare algoritmi più efficienti ed efficienti. elaborazione delle informazioni.
Sintassi e esempio di utilizzo
sintassi:

Qui $ filename è il nome del file o l'URL della pagina, $ use_include_path ti permette di cercare il file nel percorso di inclusione, $ context è la risorsa creata dal costrutto stream_context_create (), $ offset è l'offset per iniziare a leggere, $ maxlen è la quantità massima di dati da leggere .
Ad
Solitamente viene utilizzato un file PHP più semplice per il contenuto:
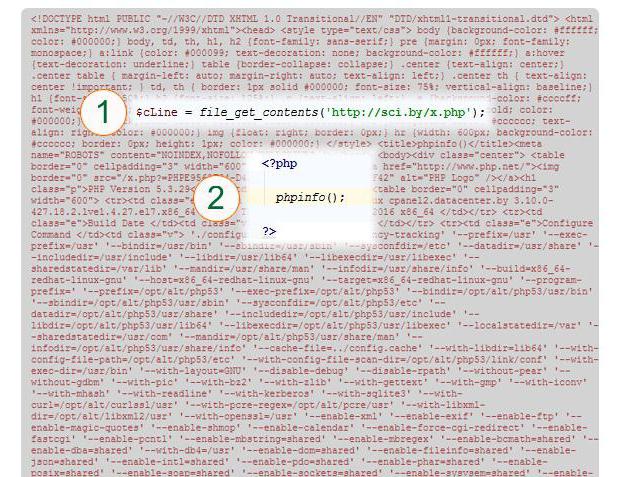 In questo esempio, il contenuto della pagina viene letto nella variabile $ cLine (1). L'URL specificato è indicato. In realtà, la pagina (2) è rappresentata dal costrutto PHP phpinfo (), cioè non è il testo di tre righe che viene letto, ma il risultato dell'esecuzione di questa funzione.
In questo esempio, il contenuto della pagina viene letto nella variabile $ cLine (1). L'URL specificato è indicato. In realtà, la pagina (2) è rappresentata dal costrutto PHP phpinfo (), cioè non è il testo di tre righe che viene letto, ma il risultato dell'esecuzione di questa funzione.
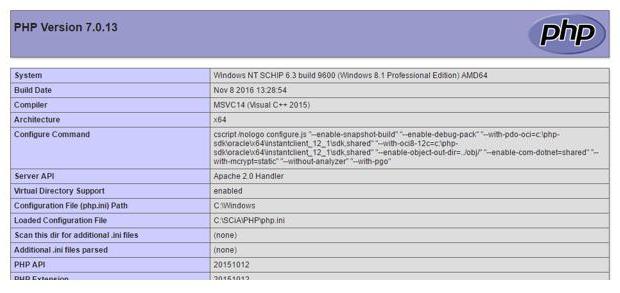
Come puoi vedere, il risultato è una pagina a tutti gli effetti, mentre il file PHP ottiene il contenuto in (http ...) legge e scrive il contenuto interno di questa pagina nella variabile $ cLine.
Opzioni e opzioni del contesto
Va tenuto presente che l'uso del parametro $ context apre grandi possibilità.

Nella pratica normale, l'uso di tutti i parametri tranne $ filename non è una regola popolare. Tuttavia, il valore creato dal costrutto stream_context_create () e utilizzato come parametro $ $ consente di scrivere algoritmi piuttosto complessi per ottenere le informazioni necessarie.
Ad
Diversi file system, i gestori di flusso (wrapper) richiedono diversi parametri e opzioni per descrivere il contesto. Può essere creato attraverso le costruzioni stream_context_create (stream_context_set_option, stream_context_set_params).
Elaborazione di pagine di massa
Invece di uno specifico l'indirizzo URL Il parametro $ filename può essere rappresentato da un nome di variabile. Ciò rende possibile l'analisi dei contenuti dei siti in modalità automatica programmabile, il riconoscimento dei nomi delle pagine, la determinazione dei collegamenti, l'estrazione delle informazioni necessarie.
È possibile creare il proprio parser del sito, motore di ricerca e programmi di scrittura per l'elaborazione di informazioni distribuite. Il compito è pertinente, interessante e pratico.
Lettura di file di testo
Non ci sono problemi, quale file da leggere. Nella seguente, versione complessa, il contenuto del file get costruzione di php è un esempio del fatto che il file "Word" può essere letto senza problemi:

Ecco un documento complesso che viene utilizzato per testare la libreria PHPOffice / PHPWord. Il file MS Word (* .docx), come sai, è un archivio zip, all'interno del quale ci sono informazioni sullo standard Open XML.
Di norma, i file di documento sono piuttosto grandi e complessi, ma il file PHP ottenuto dalla costruzione del contenuto fa fronte alla loro lettura senza difficoltà. La specificità di questo particolare esempio risiede nel fatto che l'elaborazione di un documento utilizzando esclusivamente la libreria PHPOffice / PHPWord non fornisce le funzionalità necessarie ed è semplicemente impossibile leggere il file in modo sequenziale.
Ad
In questo documento, tutti i suoi elementi (parole, paragrafi, formule, immagini, elementi di ortografia) sono descritti da una serie di tag, alcuni dei quali possono essere rappresentati da una sequenza di oggetti annidati l'uno nell'altro.
Se si prende un esempio di un documento (* .docx) con tabelle, la situazione non è affatto risolvibile con l'elaborazione sequenziale del file. Richiede almeno due passaggi attraverso il corpo del documento, se non per andare in particolare, ad esempio, quando le tabelle si annidano l'una nell'altra.
Codifica e problemi di carattere speciali
Se la lettura di file complessi non causa problemi, allora problemi con il lavoro con file semplici. Inizialmente, dovrebbe essere preso come un assioma: PHP legge il file ottenere la costruzione del contenuto correttamente. Anche se non si utilizzano determinati parametri, la versione più semplice della sua applicazione funzionerà sempre come dovrebbe.
Le difficoltà sono causate dalle parentesi angolari e dalla codifica dei file. È necessario distinguere il lavoro all'interno dell'algoritmo dalla visualizzazione del risultato in una finestra del browser. Nella figura con l'esempio del file Word, la riga (1) - $ cLine = scChangeLTGT ($ cLine) - chiama la funzione di convertire una coppia di parentesi angolari in caratteri speciali "<" e ">", altrimenti solo il file letto non può essere sempre visualizzato nella finestra del browser. Come scrivere questa funzione non è importante, ma è importante non dimenticare che le informazioni letto possono contenere tag XML e HTML, e ciò richiede un'attenzione speciale.
Ad
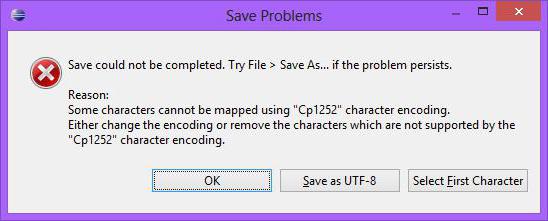
Il prossimo punto: codifica dei file. Non sempre un semplice file di testo non crea problemi. Se le informazioni di testo vengono lette, la presenza di lettere russe può creare alcune difficoltà (2).
$ cLine = iconv ('UTF-8', 'CP1251', $ cLine). In questo contesto, l'uso della funzione iconv () con la direzione di conversione corretta è rilevante non solo in relazione a "file get http://" di PHP per leggere la pagina del sito, ma anche quando viene letto un file locale ordinario.
Se il risultato della lettura è "non visibile", la prima cosa è controllare la codifica dei caratteri.